rcore记录
Last Update:
第 33 行令 a0←sp,让寄存器 a0 指向内核栈的栈指针也就是我们刚刚保存的 Trap 上下文的地址, 这是由于我们接下来要调用
trap_handler进行 Trap 处理,它的第一个参数cx由调用规范要从 a0 中获取。而 Trap 处理函数trap_handler需要 Trap 上下文的原因在于:它需要知道其中某些寄存器的值,比如在系统调用的时候应用程序传过来的 syscall ID 和 对应参数。我们不能直接使用这些寄存器现在的值,因为它们可能已经被修改了,因此要去内核栈上找已经被保存下来的值。
为什么可能已经被更改了?
run_next_task会调用find_next_task方法尝试寻找一个运行状态为Ready的应用并获得其 ID 。 如果找不到, 说明所有应用都执行完了,find_next_task将返回None,内核 panic 退出。 如果能够找到下一个可运行应用,我们就调用__switch切换任务。
切换任务之前,我们要手动 drop 掉我们获取到的TaskManagerInner可变引用。 因为函数还没有返回,inner不会自动销毁。我们只有令TASK_MANAGER的inner字段回到未被借用的状态,下次任务切换时才能再借用。
为什么呢?__switch直接切换sp,那么此时上一个任务进行到哪一步了?为什么说函数没有返回。inner在干吗?所有权保存在上一个任务(被保存的寄存器)的内存里吗?
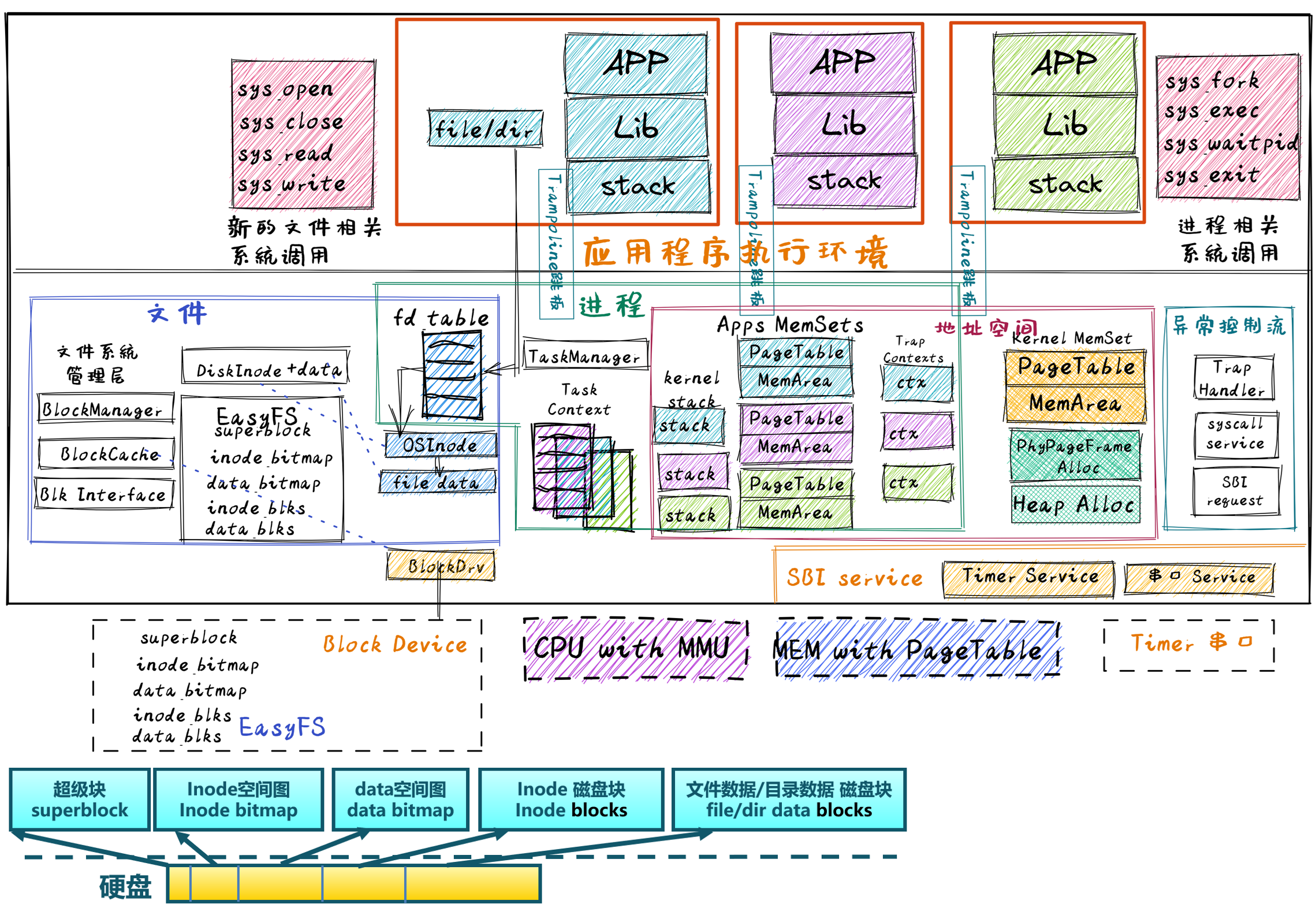
目前我们的设计是有一个唯一的内核地址空间存放内核的代码、数据,同时对于每个应用维护一个它们自己的地址空间,因此在 Trap 的时候就需要进行地址空间切换,而在任务切换的时候无需进行(因为这个过程全程在内核内完成)。而教程前两版以及 μ core 中的设计是每个应用都有一个地址空间,可以将其中的逻辑段分为内核和用户两部分,分别映射到内核和 用户的数据和代码,且分别在 CPU 处于 S/U 特权级时访问。此设计中并不存在一个单独的内核地址空间。
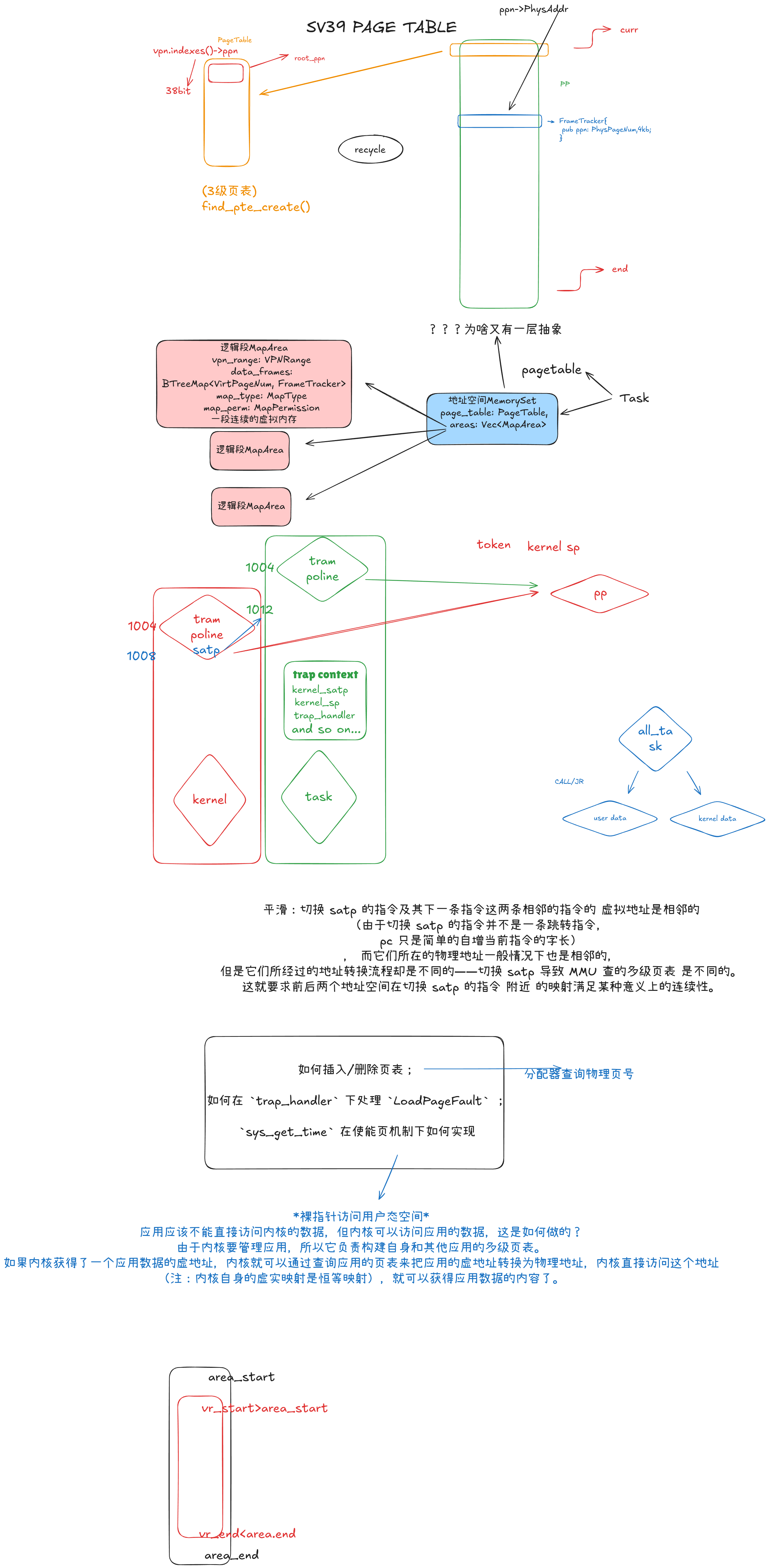
为啥 在 Trap 的时候就需要进行地址空间切换,而在任务切换的时候无需进行(因为这个过程全程在内核内完成)
无论是内核还是应用的地址空间,跳板的虚拟页均位于同样位置,且它们也将会映射到同一个实际存放这段 汇编代码的物理页帧。
同一个物理页帧?这么牛逼,虚拟地址难道也一样吗?
最后可以解释为何我们在
__alltraps中需要借助寄存器jr而不能直接call trap_handler了。因为在 内存布局中,这条.text.trampoline段中的跳转指令和trap_handler都在代码段之内,汇编器(Assembler) 和链接器(Linker)会根据linker.ld的地址布局描述,设定电子指令的地址,并计算二者地址偏移量 并让跳转指令的实际效果为当前 pc 自增这个偏移量。但实际上我们知道由于我们设计的缘故,这条跳转指令在被执行的时候, 它的虚拟地址被操作系统内核设置在地址空间中的最高页面之内,加上这个偏移量并不能正确的得到trap_handler的入口地址。
问题的本质可以概括为:跳转指令实际被执行时的虚拟地址和在编译器/汇编器/链接器进行后端代码生成和链接形成最终机器码时设置此指令的地址是不同的。
什么意思?虚拟地址是人为设定的?那么此时虚拟地址对应的是什么地方?有没有图
1 | |
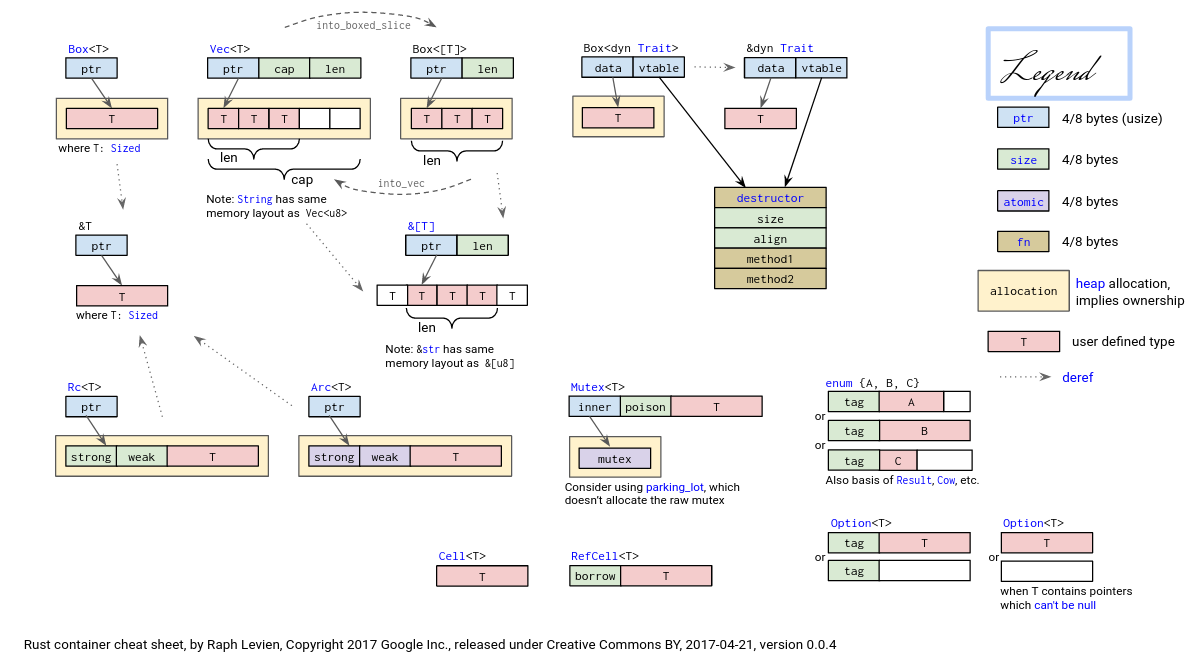
在 Rust 中,与动态内存分配相关的智能指针主要有如下这些:
Box<T>在创建时会在堆上分配一个类型为T的变量,它自身也只保存在堆上的那个变量的位置。而和裸指针或引用不同的是,当Box<T>被回收的时候,它指向的那个变量(位于堆上)也会被回收。Box<T>可以对标 C++ 的std::unique_ptr。Rc<T>是一个单线程上使用的引用计数类型,它提供了多所有权支持,即可同时存在多个智能指针指向同一个堆上变量的Rc<T>,它们都可以拿到指向变量的不可变引用来访问这同一个变量。而它同时也是一个引用计数,事实上在堆上的另一个位置维护了这个变量目前被引用的次数 N ,即存在 N 个Rc<T>智能指针。这个计数会随着Rc<T>智能指针的创建或复制而增加,并在Rc<T>智能指针生命周期结束时减少。当这个计数变为零之后,这个智能指针变量本身以及被引用的变量都会被回收。Arc<T>与Rc<T>功能相同,只是Arc<T>可以在多线程上使用。Arc<T>类似于 C++ 的std::shared_ptr。RefCell<T>与Box<T>等智能指针不同,其 借用检查 在运行时进行。对于RefCell<T>,如果违反借用规则,程序会编译通过,但会在运行时 panic 并退出。使用RefCell<T>的好处是,可在其自身是不可变的情况下修改其内部的值。在Rust语言中,在不可变值内部改变值是一种 内部可变性 的设计模式。Mutex<T>是一个互斥锁,在多线程中使用。它可以保护里层的堆上的变量同一时间只有一个线程能对它进行操作,从而避免数据竞争,这是并发安全的问题,会在后面详细说明。同时,它也能够提供 内部可变性 。Mutex<T>时常和Arc<T>配套使用,因为它是用来保护多线程(线程概念在后面会讲,这里可简单理解为运行程序)可同时访问的数据,其前提就是多个线程都拿到指向同一块堆上数据的Mutex<T>。于是,要么这个Mutex<T>作为全局变量被分配到数据段上,要么将Mutex<T>包裹上一层多所有权Arc,变成Arc<Mutex<T>>这种经典组合结构,让最里层基于泛型T数据结构的变量可以在线程间安全传递。在讲解 同步互斥 之前我们通过
RefCell<T>来获得内部可变性。可以将Mutex<T>看成RefCell<T>的多线程版本, 因为RefCell<T>是只能在单线程上使用的。而且RefCell<T>并不会在堆上分配内存,它仅用于基于数据段的静态内存 分配。
基于上述智能指针,可形成更强大的 集合 (Collection) 或称 容器 (Container) 类型,它们负责管理一组数目可变的元素,这些元素的类型相同或是有着一些同样的特征。在 C++/Python/Java 等高级语言中我们已经对它们的使用方法非常熟悉了,对于 Rust 而言,我们可以直接使用以下容器:
向量
Vec<T>类似于 C++ 中的std::vector;键值对容器
BTreeMap<K, V>类似于 C++ 中的std::map;有序集合
BTreeSet<T>类似于 C++ 中的std::set;链表
LinkedList<T>类似于 C++ 中的std::list;双端队列
VecDeque<T>类似于 C++ 中的std::deque。变长字符串
String类似于 C++ 中的std::string。
有对比才有更深入的理解,让我们先来看其它一些语言使用动态内存的方式:
C 语言仅支持
malloc/free这一对操作,它们必须恰好成对使用,否则就会出现各种内存错误。比如分配了之后没有回收,则会导致内存泄漏;回收之后再次 free 相同的指针,则会造成 Double-Free 问题;又如回收之后再尝试通过指针访问它指向的区域,这属于 Use-After-Free 问题。总之,这样的内存安全问题层出不穷,毕竟人总是会犯错的。Python/Java 通过 引用计数 (Reference Counting) 对所有的对象进行运行时的动态管理,一套 垃圾回收 (GC, Garbage Collection) 机制会被自动定期触发,每次都会检查所有的对象,如果其引用计数为零则可以将该对象占用的内存从堆上回收以待后续其他的对象使用。这样做完全杜绝了内存安全问题,但是性能开销则很大,而且 GC 触发的时机和每次 GC 的耗时都是无法预测的,还使得软件的执行性能不够确定。
C++ 的智能指针(shared_ptr、unique_ptr、weak_ptr、auto_ptr等)和 资源获取即初始化 (RAII, Resource Acquisition Is Initialization,指将一个使用前必须获取的资源的生命周期绑定到一个变量上,变量释放时,对应的资源也一并释放。) 风格都是致力于解决内存安全问题。但这些编程方式是“建议”而不是“强制”。
可以发现,在动态内存分配方面, Rust 和 C++ 很像,事实上 Rust 有意从 C++ 借鉴了这部分优秀特性,并强制Rust编程人员遵守 借用规则 。以 Box<T> 为例,在它被创建的时候,会在堆上分配一块空间保存它指向的数据;而在 Box<T> 生命周期结束被回收的时候,堆上的那块空间也会立即被一并回收。这也就是说,我们无需手动回收资源,它和绑定的变量会被自动回收;同时,由于编译器清楚每个变量的生命周期,则变量对应的资源何时被回收是完全可预测的,回收操作的开销也是确定的。在 Rust 中,不限于堆内存,将某种资源的生命周期与一个变量绑定的这种 RAII 的思想无处不在,甚至这种资源可能只是另外一种类型的变量。
进入用户态时,上下文在切换空间后恢复。为什么不能在之前恢复呢?是因为如果这样做,那么在系统调用、中断等情形需要陷入内核时,需要保存上下文,这些上下文包括内核的地址空间配置,此时就没有地方得知内核的地址空间如何设置了。所以上下文恢复应当在跳板页中用户空间执行的部分。因为每个用户程序需要一个上下文,因此每个处理核都应当有一个跳板数据页,而跳板代码页可以共享同一个。
我们注意到,地址空间切换完成后,特权级的切换并未立即完成。进入新的地址空间后,跳板页的剩余部分将完成特权级的切换流程。因此,跳板页在所有的地址空间下,无论是内核还是用户的空间,都应只有内核特权级可见。跳板代码页和跳板数据页都应当遵守这个规则。
什么意思????
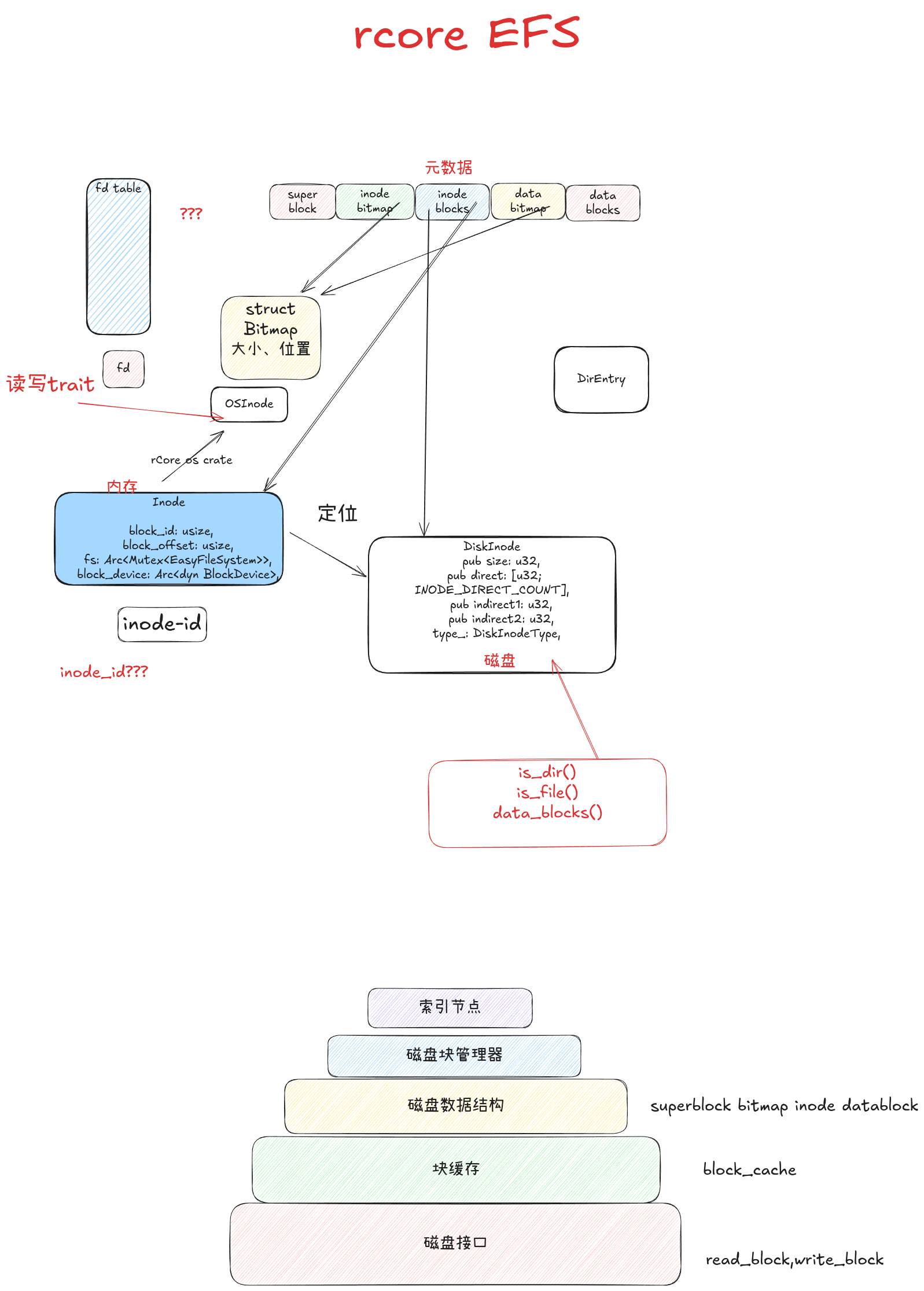
实现地址空间的第一步就是实现分页机制,建立好虚拟内存和物理内存的页映射关系。此过程需要硬件支持,硬件细节与具体CPU相关,涉及地址映射机制等,相对比较复杂。总体而言,我们需要思考如下问题:
硬件中物理内存的范围是什么?
哪些物理内存空间需要建立页映射关系?
如何建立页表使能分页机制?
如何确保 OS 能够在分页机制使能前后的不同时间段中都能正常寻址和执行代码?
页目录表(一级)的起始地址设置在哪里?
二级/三级等页表的起始地址设置在哪里,需要多大空间?
如何设置页目录表项/页表项的内容?
如果要让每个任务有自己的地址空间,那每个任务是否要有自己的页表?
代表应用程序的任务和操作系统需要有各自的页表吗?
在有了页表之后,任务和操作系统之间应该如何传递数据?
如果能解决上述问题,我们就能设计实现具有超强防护能力的侏罗纪“头甲龙”操作系统。并可更好地理解地址空间,虚拟地址等操作系统的抽象概念与操作系统的虚存具体实现之间的联系。
如何插入/删除页表;
如何在 trap_handler 下处理 LoadPageFault ;
sys_get_time 在使能页机制下如何实现