二分 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public :int searchInsert (vector<int >& nums, int target) int n = nums.size ();int left = 0 ;int right = n;int mid = 0 ;while (left<right){1 ;if (target<nums[mid]){else if (target>nums[mid]){+1 ;else return mid;return right;
评价:板子,多背。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution {public :bool searchMatrix (vector<vector<int >>& matrix, int target) int l = 0 ;int r = matrix.size ();int res =0 ;while (l<r){int mid = l+((r-l)>>1 );if (target>matrix[mid][0 ]){+1 ;else if (target<matrix[mid][0 ]){else return true ;-1 ;if (res < 0 || res >= matrix.size ()) {return false ;int l2=0 ;int r2 =matrix[res].size ();while (l2<r2){int mid2 = l2+((r2-l2)>>1 );if (target>matrix[res][mid2]){+1 ;else if (target<matrix[res][mid2]){else return true ;return false ;
评价:太几把猪鼻了,在res<0里纠结了很久,以及,l是第一个大于target的行索引。
循环结束时,l 和 r 会相等,且 l 是第一个大于或等于 target 的行索引。
因此,res = l - 1 是最后一个小于 target 的行索引。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {int lower_bound (vector<int > &nums,int target) int left = -1 ,right=nums.size ();while (left+1 <right){int mid = left+(right-left)/2 ;if (nums[mid]<target){else {return right;public :vector<int > searchRange (vector<int >& nums, int target) {int start = lower_bound (nums,target);if (start==nums.size ()||nums[start]!=target)return {-1 ,-1 };int end = lower_bound (nums,target+1 )-1 ;return {start,end};
评价:用0x3f的开区间写法,left right是循环不变量,left必定指向小于target的数,而right必定指向大于等于target的数
二叉树 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public :void inorder (TreeNode* root,vector<int >& res) if (!root){return ;inorder (root->left,res);push_back (root->val);inorder (root->right,res);vector<int > inorderTraversal (TreeNode* root) {
太史公曰:
中序遍历的递归实现
1 2 3 4 5 6 7 8 9 10 11 12 13 const inorderTraversal = (root ) => {const res = [];const inorder = (root ) => {if (root == null ) {return ;inorder (root.left ); push (root.val ); inorder (root.right ); inorder (root);return res;
我之前提过,我们不能含糊地记说:“中序遍历是先访问左子树,再访问根节点,再访问右子树”。
这么描述是不准确的,容易产生误导。
事实上,无论是前、中、后序遍历,都是先访问根节点,再访问它的左子树,再访问它的右子树。
那它们之间的区别在哪里?
比如中序遍历,它是将 do something with root(处理当前节点)放在了访问完它的左子树之后。
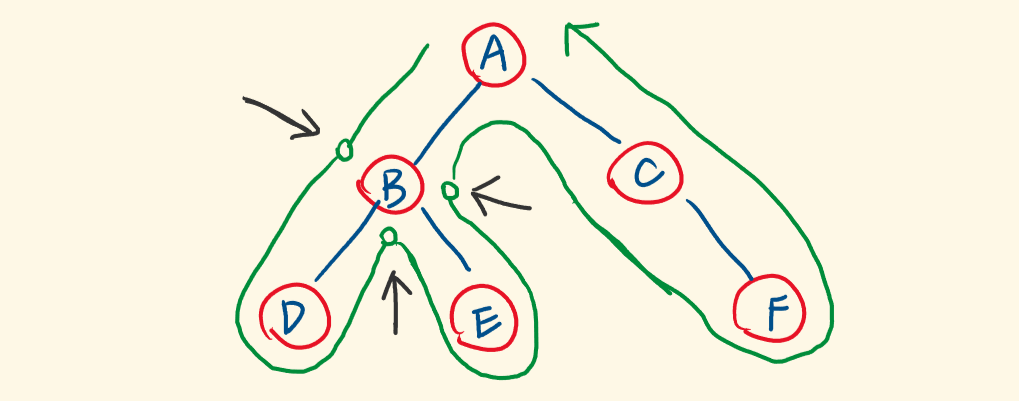
前、中、后序遍历都是基于DFS,节点的访问顺序如上图所示,每个节点有三个不同的驻留阶段,即每个节点会被经过三次:
在递归它的左子树之前。
所以,它们的唯一区别是:在什么时间点去处理节点,去拿他做文章。
所以『中序遍历』的模板如下:
1 2 3 4 5 norder (root) {
中序遍历的迭代实现
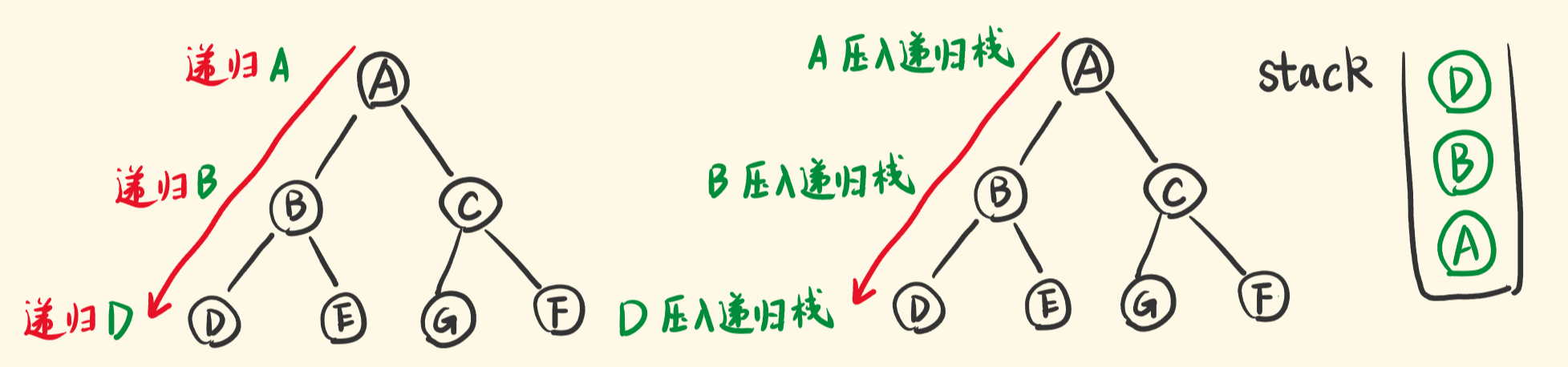
递归遍历一棵树,如下图,会先递归节点A,再递归B,再递归D,一个个压入递归栈。
即,先不断地将左节点压入栈,我们写出这部分代码:
while (root) {
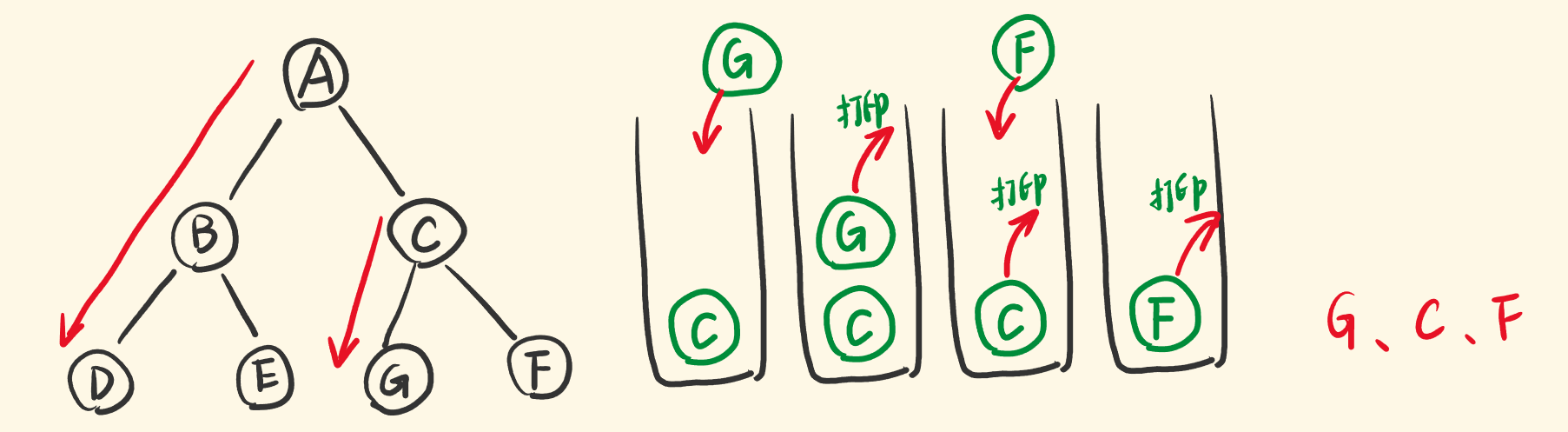
并且是先访问『位于树的底部的』即『位于栈的顶部的』节点的右子树。
于是,让栈顶节点出栈,出栈的同时,把它的右子节点压入栈,相当于递归右子节点。
因为是中序遍历,在栈顶节点的右子节点压栈之前,要处理出栈节点的节点值,将它输出。
新入栈的右子节点(右子树),就是在递归它。和节点A、B、D的压栈一样,它们都是子树。
不同的子树要做同样的事情,一样要先将它的左子节点不断压栈,然后再出栈,带出右子节点入栈。
即栈顶出栈的过程,也要包含下面代码,可见下面代码重复了两次:
while (root) {
inorder(root.left);
while (root) { // 能压栈的左子节点都压进来
1 2 3 4 5 6 7 8 9 10 11 12 13 const inorderTraversal = (root ) => {const res = [];const inorder = (root ) => {if (root == null ) {return ;inorder (root.left );push (root.val );inorder (root.right );inorder (root);return res;
全流程大致图示
明确这三种遍历都是基于DFS递归,清楚概念,再明白递归其实是压栈出栈的操作,比照着,用一个栈,去模拟递归栈,用迭代,去模拟递归的逻辑,就不难写出迭代法的代码。
回溯 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {private :int >> res;int > path;void dfs (vector<int > nums,int x,vector<bool > used) if (x==nums.size ()){push_back (path);return ;for (int i = 0 ;i<nums.size ();i++){if (used[i])continue ;true ;push_back (nums[i]);dfs (nums,x+1 ,used);false ;pop_back ();public :int >> permute (vector<int >& nums) {int n = nums.size ();vector<bool > used (n) ;dfs (nums,0 ,used);return res;
评价:循环该从0开始,每次都是遍历整个数组找没用过的数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution {private :int >> res;int > path;void dfs (vector<int > nums,int x) push_back (path);for (int i = x;i<nums.size ();i++){push_back (nums[i]);dfs (nums,i+1 );pop_back ();public :int >> subsets (vector<int >& nums) {dfs (nums,0 );return res;
评价:dfs参数是i+1,避开已经看过的数
前缀和与子串 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class NumArray {
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 class Solution {public :int subarraySum (vector<int >& nums, int k) vector<int > s (nums.size()+1 ) ;int ,int > cnt;0 ]=0 ;for (int i=0 ;i<nums.size ();i++){+1 ]=s[i]+nums[i];int ans = 0 ;for (int i =0 ;i<s.size ();i++){return ans; class Solution {public :int subarraySum (vector<int >& nums, int k) vector<int > s (nums.size()+1 ) ;int ,int > cnt;0 ]=0 ;for (int i=0 ;i<nums.size ();i++){+1 ]=s[i]+nums[i];int ans = 0 ;for (int i =0 ;i<s.size ();i++){return ans; class Solution {public :int subarraySum (vector<int >& nums, int k) vector<int > s (nums.size()+1 ) ;int ,int > cnt;int ans = 0 ;for (int i=0 ;i<nums.size ();i++){+1 ]=s[i]+nums[i];for (int i=0 ;i<s.size ();i++) {contains (s[i] - k) ? cnt[s[i] - k] : 0 ;return ans;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public :vector<int > maxSlidingWindow (vector<int >& nums, int k) {int > res;int n = nums.size ();int ,int >> p;for (int r = 0 ;r<nums.size ();r++){push ({nums[r],r});if (p.size ()>=k){while (p.top ().second<=r-k){pop ();push_back (p.top ().first);return res;